�Լ� c t − 1 c_{t-1}ct−1 ����t֮ǰ���е�ʱ����Ϣ�������ڼ���״̬c cc��ConvLSTM���г��ڼ��������, ������Conv����tʱ�̵���������֮ǰ״̬��һ���˶���Ϣ���������ھ���ʱ�ĸ���Ұ�Ƚ�С������ConvLSTM��������˶����������ޣ�����ᵼ�´�����Ϣ�IJ��ϴ������ۻ���
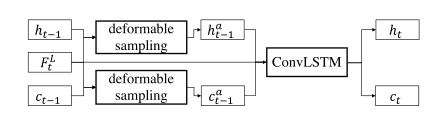
Ϊ�˸��ô�������˶�����Ƶ����ƪ������ConvLSTM��Ƕ���˿ɱ��ξ������������ÿɱ��ξ����ֱ�[ h t − 1 , F t L ] [h_{t-1},F^L_t][ht−1,FtL]��c t − 1 , F t L ] c_{t-1},F^L_t]ct−1,FtL]֮���������Ϣ��ʵ��ʱ���ϵĶ��룬�õ�[ h t − 1 a , c t − 1 a ] [h^a_{t-1},c^a_{t-1}][ht−1a,ct−1a] ,Ȼ��������ConvLSTM��������ʱ����Ϣ�ľۼ��������ںϣ������´��������̵�ʾ��ͼ������ʾ��
ͼ3 Ƕ��ɱ��ξ�����ConvLSTM
ͬʱ��Ϊ�˸�������ȫ�ֵ�ʱ����Ϣ��ʵ����ʹ����˫��Ŀɱ��� ConvLSTM��Bidirectional Deformable ConvLSTM��,�����ں��˹�ȥ��δ����Ϣ����������{ h t } t 2 n + 1 \{h_t\}^{2n+1}_t{ht}t2n+1��
2.3 ֡�ؽ�ģ��
֡�ؽ�ģ������ʹ����һ��ʱ�乲���ĺϳ����������뵱��ʱ�䲽������״̬h t h_tht��Ȼ�������Ӧ��HR frame��������˵����ʹ����k 2 k_2k2���в����ȡ���������Ϣ��Ȼ��ͨ�������ؾ�����sub-pixel��+PixelShuffle�ؽ���HR frames { I t t } t = 1 2 n + 1 \{I^t_t\}^{2n+1}_{t=1}{Itt}t=12n+1���ؽ���ʧ�������£� l r e c = �O �O I G T t − I t H �O �O 2 + ϵ 2 l_{rec}=\sqrt {||I^GT_t-I^H_t||^2+\epsilon^2}lrec=�O�OIGTt−ItH�O�O2+ϵ2
ϵ 2 \epsilon^2ϵ2��һ������ֵ������Ϊ1e-3��Ϊ�˱�֤ѵ�����ȶ��ԣ�����Ϊ����ֵ�ȶ�---->ѵ���ȶ���
�������Ķ��η�������VFI��VSR�е�SOTAģ�������ɣ���������Zooming Slow-Mo���������ϵı��ֶ����ã�����������һ��ģ�ͣ�ģ�͵IJ������Ƚ�С���������ٶȱ�������ģ�Ͷ�Ҫ��öࡣ��TiTan XP Vid4�ϲ��ԣ�