mysql 表外连接
外连接
1.左外连接(如果左侧的表完全显示我们就说是左外连接)
2.右外连接(如果右侧的表完全显示我们就说是右外连接)
3.使用左连接(显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,成绩显示为空)
select.from表1 left join表2 on条件 [表1:就是左表表2:就是右表]
4.使用右外连接(显示所有成绩,如果没有名字匹配,显示空)
select . from 表1 right join 表2 on条件[表1:就是左表表2:就是右表]
mysql 约束
基本介绍
约束用于确保数据库的数据满足特定的商业规则。在mysql中,约束包括:
not null、 unique,primary key,foreign key,和check 五种.
primary key(主键)-基本使用

primary key(主键)-细节说明
- primary key能重复而且能null。
- 一张表最多只能有一个主键,但可以是复合主键
主键的指定方式有两种
-
直接在字段名后指定:字段名primakry key
-
在表定义最后写 primary key(列名);
-
使desc表,可以看到primary key的情况.
-
提醒:在实际开发中,每个表往往都会设计一个主键
not null(非空)

unique(唯一)

unique 细节(注意):
- 如果没有指定 not null,则 unique 字段可以有多个null
- 一张表可以有多个unique字段
foreign key(外键)
用于定义主表和从表之间的关系:
外键约束要定义在从表上,主表则必须具有主键约束或是unique约束.,
当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null

foreign key(外键)一细节说明
- 外键指向的表的字段,要求是primary key或者是unique
- 表的类型是innodb,这样的表才支持外键
- 外键字段的类型要和主键字段的类型一致(长度可以不同)
- 外键字段的值,必须在主键字段中出现过,或者为null[前提是外键字段允许为null]
- 一旦建立主外键的关系,数据不能随意删除了
check
用于强制行数据必须满足的条件,假定在sal列上定义了check约束,并要求sal列值在10002000之间如果不再10002000之间就会提示出错。
提示: oracle 和 sql server均支持check,但是mysql5.7目前还不支持check,只做语法校验,但不会生效。check.sql在mysql中
实现check的功能,一般是在程序中控制或者通过触发器完成。

自增长


-
一般来说自增长是和primary key配合使用的
-
自增长也可以单独使用[但是需要配合一个unique]
-
自增长修饰的字段为整数型的(虽然小数也可以但是非常非常少这样使用)
-
自增长默认从1开始,你也可以通过如下命令修改alter table表名 auto_increment =新的始值;
-
如果你添加数据时,给自增长字段(列)指定的有值,则以指定的值为准,如果指定了自增长,一般来说,就按照自增长的规则来添加数据
mysql 索引
索引的原理
没有索引为什么会慢?因为全表扫描
使用索引为什么会快?形成一个索引的数据结构,比如二叉树索
引的代价
- 磁盘占用
- 对dml(update delete insert)语句的效率影响
在我们项目一般是中,select多 (update,delete,insert)少
索引的类型
- 主键索引,主键自动的为主索引用(类型Primary key)
- 唯一索引(UNIQUE)
- 普通索引(INDEX)
- 文索引(FULLTEXT)[适用于MyISAM]
一般开发,不使用mysql自带的全文索引,而是使用:全文搜索Solr和 ElasticSearch(ES)

索引使用
添加索引
- create [UNIQUE] index index_name on tbl_name (col_name [(length)][ASC | DESC],…);
- alter table table_name ADD INDEX [index name] (index col name,.)
- 添加主键(索引)
ALTER TABLE表名ADD PRIMARY KEY(列名,.);
删除索引
- DROP INDEX index_name ON tbl_name;
- alter table table_name drop index index_name;
- 删除主索引比较特别:
alter table t_b drop primary key;
- 查询索引(三种方式)
- show index(es) from table_name;
- show keys from table_name;
- desc table_Name;
小结
较频繁的作为查询条件字段应该创建索引
select * from emp where empno = 1
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
select * from emp where sex = '男
更新非常频繁的字段不适合创建索引
select * from emp where logincount = 1
不会出现在WHERE子句中字段不该创建索引
mysql 事务
什么是事务
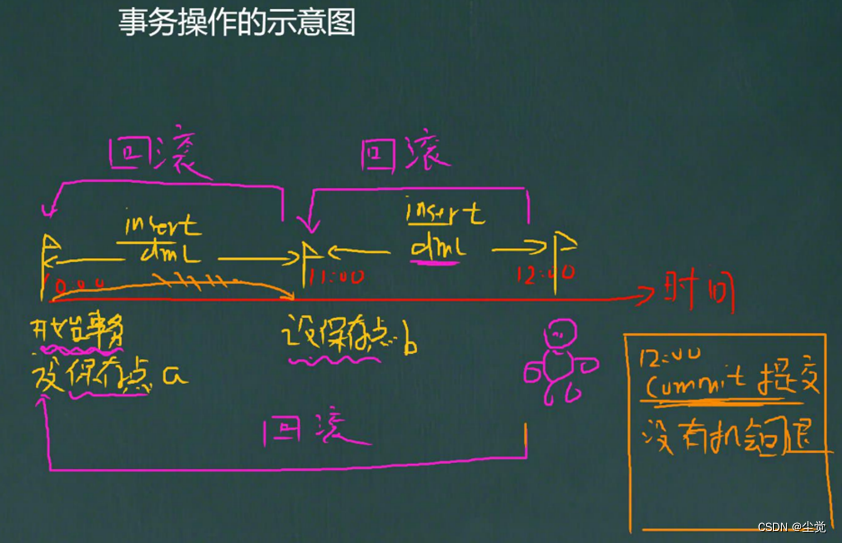
事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml语句要么全部成功,要么全部失败。
如:转账就要用事务来处理,用以保证数据的一致性。
事务和锁
当执行事务操作时(dml语句),mysql会在表上加锁,防止其它用户改表的数据.这对用户来讲是非常重要的
mysql 数据库控制台事务的几个重要操作
- start transaction -开始一个事务
- savepoint保存点名-设置存点
- rollback to保存点名-回退事务
- rollback-回退全部事务
- commit-提交事务,所有的操作生效,不能回退
回退事务
在介绍回退事务前,先介绍一下保存点(savepoint).
保存点是事务中的点.用于取消部分事务,当结束事务时(commit),
会自动的删除该事务所定义的所有保存点当执行回退事务时,通过指定保存点可以回退到指定的点
提交事务
使用commit语句可以提交事务.当执行了commit语句子后,会确认事务的变化、结束事务、删除保存点、释放锁,数据生效。
当使用commit语句结束事务子后,其它会话[其他连接]将可以查看到事务变化后的新数据[所有数据就正式生效.]
事务细节讨论
- 如果不开始事务,默认情况下,dml操作是自动提交的,不能回滚
- 如果开始一个事务,你没有创建保存点.你可以执行rollback,默认就是回退到你事务开始的状态
- 你也可以在这个事务中(还没有提交时),创建多个保存点.比如:savepoint aaa;执行 dml, savepoint bbb;
- 你可以在事务没有提交前,选择回退到哪个保存点
- mysql的事务机制需要innodb的存储引擎才可以使用,myisam不好使.
- 开始一个事务 start transaction, set autocommit=off;
mysql 事务隔离级别
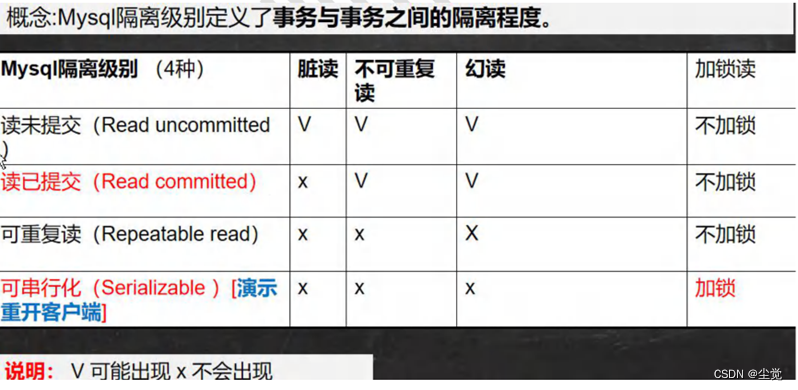
事务隔离级别介绍
多个连接开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性。(通俗解释)
如果不考虑隔离性,可能会引发如下问题:
查看事务隔离级别
- 脏读(dirty read):当一个事务读取另一个事务尚未提交的改变(update,insert,delete)时,产生脏读
- 不可重复读(nonrepeatable read):同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生不可重复读
- 幻读(phantom read):同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读
事务隔离级别
设置事务隔离级别
查看当前会话隔离级别
select @@tx isolation;
查看系统当前隔离级别
select @@global.tx isolation;
设置当前会话隔离级别
set session transaction isolation level repeatable read;
设置系统当前隔离级别
set global transaction isolation level repeatable read;
mysql 默认的事务隔离级别是 repeatable read,
一般情况下,没有特殊要求,没有必要修改(因为该级别可以满足绝大部分项目需求)

mysql事务 ACID
事务的 acid 特性
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态
隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
mysql 表类型和存储引擎
基本介绍
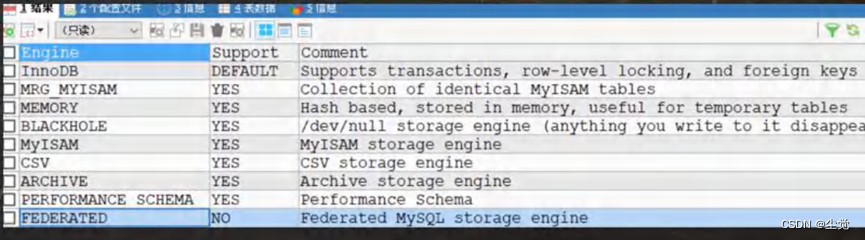
MySQL的表类型由存储引擎(Storage Engines)决定
主要包括MyISAM、innoDB、Memory等
- MySQL数据表主要支持六种类型,分别是:CSV、Memory、ARCHIVE, MRG_MYISAM、 MYISAM、 InnoBDB。
- 这六种又分为两类,一类是”事务安全型”(transaction-safe),比如:InnoDB;
其余都属于第二类,称为”非事务安全型”(non-transaction-safe)[mysiam 和 memory]
主要的存储引擎/表类型特点
细节说明
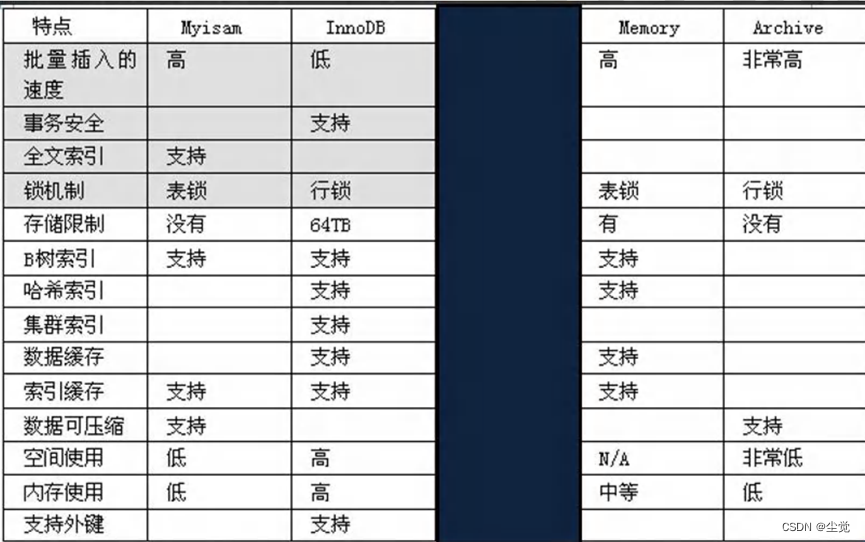
- MylSAM不支持事务、也不支持外键,但其访问速度快,对事务完整性没有要求
- InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。
但是比起MylSAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
MEMORY存储引擎使用存在内存中的内容来创建表。
每个MEMORY表只实际对应一个磁盘文件。MEMORY类型的表访问非常得快,
因为它的数据是放在内存中的,并且默认使用HASH索引。但是一旦MySQL服务关闭,表中的数据就会丢失掉,表的结构还在。
如何选择表的存储引擎
如果你的应用不需要事务,处理的只是基本的CRUD操作,
那么MylSAM是不二选择,速度快
- 如果需要支持事务,选择InnoDB。
- Memory存储引擎就是将数据存储在内存中,由于没有磁盘I./O的等待,速度极快。
但由于是内存存储引擎,所做的任何修改在服务器重启后都将消失。
(经典用法用户的在线状态().)
修改存储引擎

视图(view)
基本概念
视图是一个虚拟表,其内容由查询定义。同真实的表一样,
视图包含列,其数据来自对应的真实表(基表)
视图和基表关系的示意图

视图的基本使用
- create view 视图名 as select语句
- alter view 视图名 as select语句 -更新成新的视图
- SHOW CREATE VIEW
- drop view视图名1,视图名2
视图的细节
-
创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式: 视图名.frm)
-
视图的数据变化会影响到基表,基表的数据变化也会影响到视图[insert update delete ]
-
视图中可以再使用视图 , 比如从 view01 视图中,选出 字段 做出新视图
视图最佳实践
安全。一些数据表有着重要的信息。有些字段是保密的,不能让用户直接看到。
这时就可以创建一个视图,在这张视图中只保留一部分字段。
这样,用户就可以查询自己需要的字段,不能查看保密的字段。
性能。关系数据库的数据常常会分表存储,使用外键建立这些表的之间关系。
这时,数据库查询通常会用到连接(JOIN)。这样做不但麻烦,效率相对也比较低。
如果建立一个视图,将相关的表和字段组合在一起,就可以避免使用JOIN查询数据。
灵活。如果系统中有一张旧的表,这张表由于设计的问题,即将被废弃。
然而,很多应用都是基于这张表,不易修改。这时就可以建立一张视图,
视图中的数据直接映射到新建的表。这样,就可以少做很多改动,也达到了升级数据表的目的。
Mysql 管理
mysql中的用户,都存储在系统数据库mysql中 user 表中

其中user表的重要字段说明:
1.host: 允许登录的“位置”,
localhost表示该用户只允许本机登录,也可以指定ip地址,比如:192.168.1.100
-
user: 用户名;
-
authentication_string:
密码,是通过mysql的password()函数加密之后的密码。
创建用户
create user ‘用户名’ ‘@’ ‘允许登录位置’ identified by ’密码’
说明:创建用户,同时指定密码
删除用户
drop user ‘用名’ ‘@’ ‘允许登录位置’;
用户修改密码
修改自己的密码:
set password = password('密码');
修改他人的密码(需要有修改用户密码权限):
set password for '用户名'@'登录位置' = password('密码');
mysql 中的权限
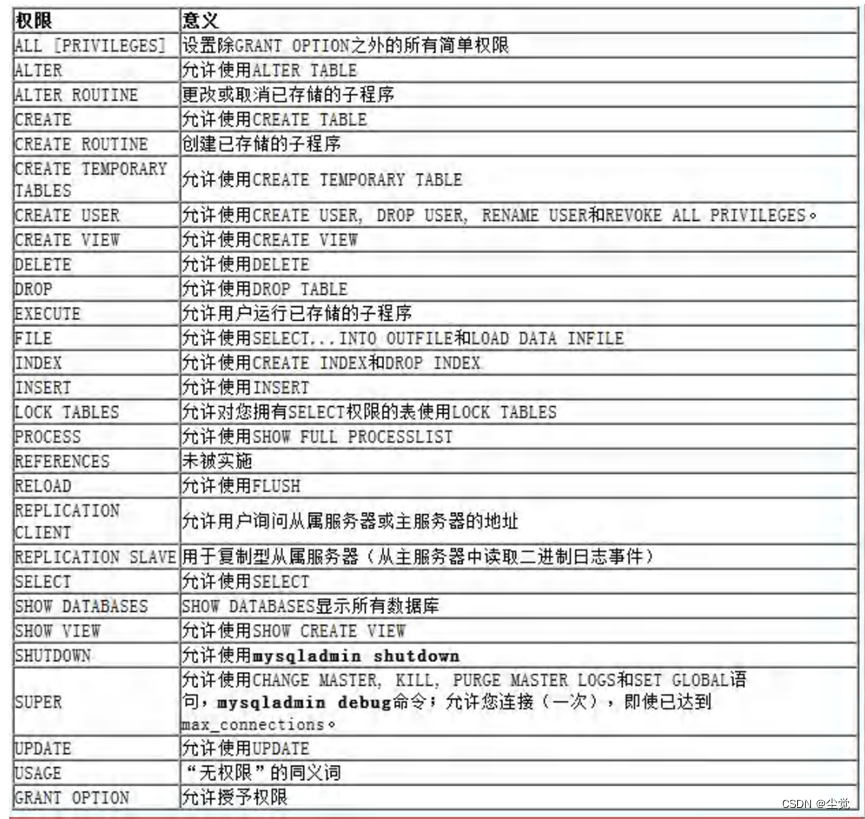
给用户授权
基本语法:
grant权限列表on库.对象名 to ‘用户名’ ‘@’ ‘登录位置’ 【identified by'密码'】
说明:
-
权限列表,多个权限用逗号分开
-
grant select on …
-
grant select, delete, create on …
-
grant all 【privileges】 on… //表示赋予该用户在该对象上的所有权限
特别说明
*.*:代表本系统中的所有数据库的所有对象(表,视图,存储过程)
库.*:表示某个数据库中的所有数据对象(表,视图,存储过程等)
identified by可以省略,也可以写出
如果用户存在,就是修改该用户的密码。
如果该用户不存在,就是创建该用户!
回收用户授权
基本语法:
revoke 权限列表 on 库**.**对象名 from '用户名’ ‘@‘ ‘登录位置';
权限生效指令
如果权限没有生效,可以执行下面命令
基本语法:
FLUSH PRIVILEGES;
细节说明
在创建用户的时候,如果不指定Host,则为%,
%表示表示所有IP都有连接权限create user xxx;
你也可以这样指定create user ‘xxx’ ‘@’ ’19168.1.%’
表示 xxx用户在192.168.1.*的ip可以登录mysql
予该用户在该对象上的所有权限
特别说明
*.*:代表本系统中的所有数据库的所有对象(表,视图,存储过程)
库.*:表示某个数据库中的所有数据对象(表,视图,存储过程等)
identified by可以省略,也可以写出
如果用户存在,就是修改该用户的密码。
如果该用户不存在,就是创建该用户!
回收用户授权
基本语法:
revoke 权限列表 on 库**.**对象名 from '用户名’ ‘@‘ ‘登录位置';
权限生效指令
如果权限没有生效,可以执行下面命令
基本语法:
FLUSH PRIVILEGES;
细节说明
在创建用户的时候,如果不指定Host,则为%,
%表示表示所有IP都有连接权限create user xxx;
你也可以这样指定create user ‘xxx’ ‘@’ ’19168.1.%’
表示 xxx用户在192.168.1.*的ip可以登录mysql
在删除用户的时候,如果host不是%,需要明确指定 ’用户’ ’@’ host值'
| 
